
Mixture-of-Recursions (MoR): faster LLMs by letting hard tokens “think” deeper
Mixture-of-Recursions (MoR) is a Transformer variant that reuses the same block of layers multiple times and lets each token decide how many passes it needs. Lightweight routers pick which tokens take another pass, while a tailored KV-cache scheme cuts memory traffic. The paper reports MoR matches or beats standard Transformers on accuracy with fewer parameters, and delivers higher inference throughput (up to ~2x in the paper’s setup).
Why this matters
Bigger language models are powerful but expensive to train and serve. Prior efficiency tricks usually pick one of two directions:
-
Parameter efficiency (reuse or share weights), or
-
Adaptive computation (spend more compute only on harder inputs).
MoR does both at once inside a single architecture.
The core idea
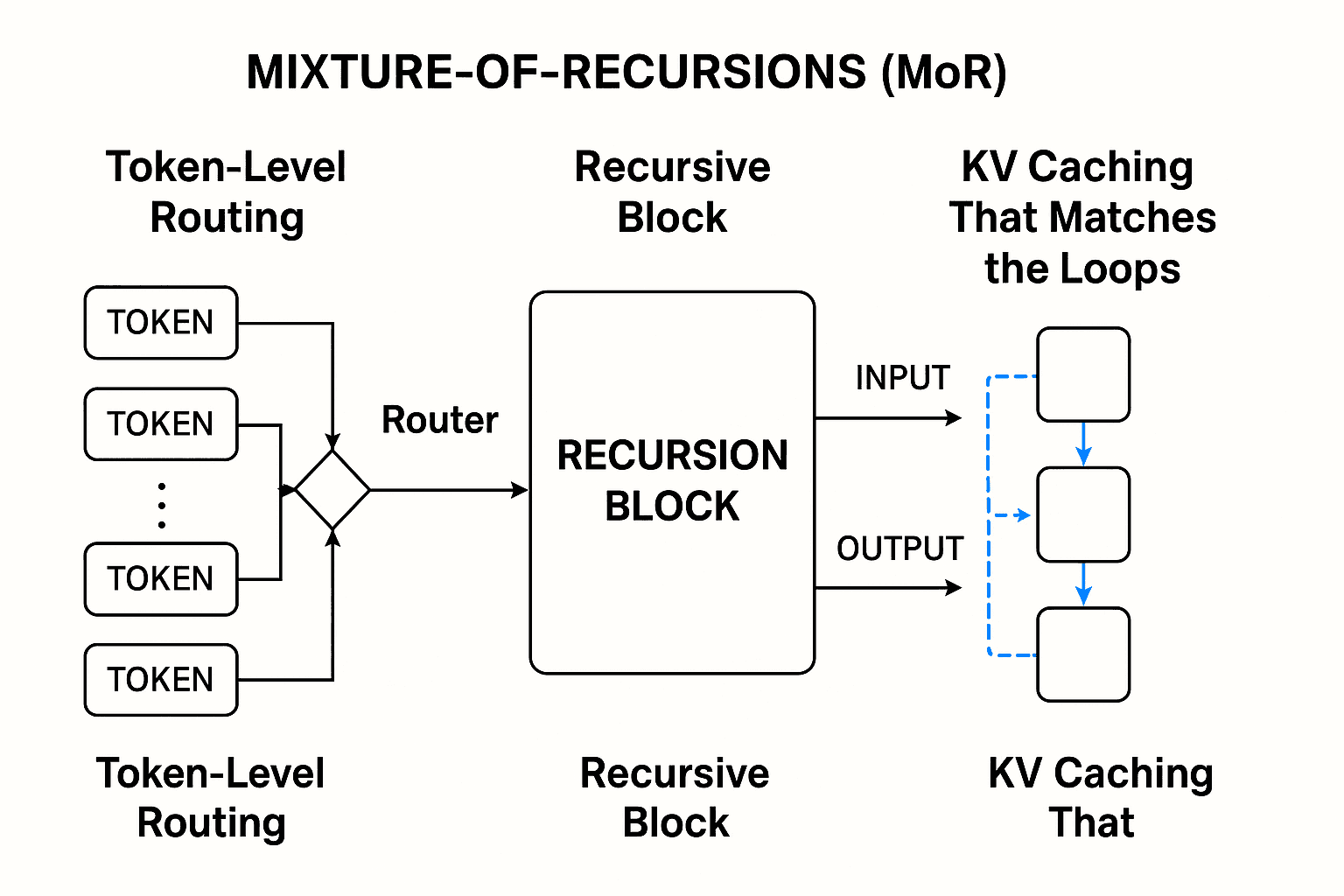
Recursive block
Instead of LLL different layers, MoR uses a shared stack (a “recursion block”) and can loop through it up to Nr times. This cuts the number of unique parameters.
Token-level routing
A small router at each recursion step decides which tokens should loop again. Two routing styles are studied:
-
Expert-choice: at each step, pick the top-k tokens to continue.
-
Token-choice: up front, assign each token a fixed number of loops.
In the paper’s experiments, expert choice gave stronger accuracy.
KV caching that matches the loops
MoR uses cache designs that fit dynamic depth:
-
Recursion-wise KV caching: cache keys/values only for tokens that continue to this depth. Others don’t add cache entries.
-
Recursive KV sharing: cache once at the first loop and reuse across later loops (helps prefill/memory, with trade-offs).
Together, these reduce parameters, FLOPs, and memory I/O while aiming to keep or improve quality.
What the paper reports
-
Model scales evaluated: base sizes from 135M to 1.7B parameters. Across these scales, MoR sets a new compute-vs-quality Pareto frontier versus vanilla and prior recursive baselines.
-
Accuracy vs size: With two recursions (Nr=2), MoR achieves 43.1% vs 42.3% average few-shot accuracy compared to a vanilla baseline while using roughly ~50% fewer parameters (because the block is shared).
-
Training efficiency (fixed tokens): ~25% fewer training FLOPs, ~19% shorter training time, and ~25% lower peak memory than the vanilla baseline in the paper’s setup.
-
Inference throughput: Under a batched serving setup called “continuous depth-wise batching,” the paper shows MoR variants at ~1.3× to ~2.18× throughput vs the vanilla model on the quality-throughput Pareto plot. The project README summarizes this as “up to 2x.” Exact gains depend on routing/caching choices and load.
Notes: Few-shot accuracy is the average across the reported benchmarks, throughput is tokens/sec under the described serving setup, and numbers vary by model size and configuration.
How MoR differs from other ideas
-
vs. Early-exiting: MoR routes at the recursion depth with a reused block, the KV-cache strategy is designed so that early exits don’t break later attention steps.
-
vs. MoE: MoR doesn’t add new experts. It reuses one block multiple times and allocates depth per token, not different expert parameters.
Expert choice routing
# Inputs:
# H0: hidden states after embedding
# block(): the shared recursion block (reused)
# router_r(): router at recursion step r (scores tokens)
# Nr: max recursion steps
# budget[r]: how many tokens may continue at step r
# caching: "recursion-wise" or "recursive-sharing"
H = H0
active = all_tokens()
# precompute and cache for recursive-sharing
if caching == "recursive-sharing":
KV[1] = kv_from(block, H) # cache once at first recursion
for r in 1..Nr:
scores = router_r(H[active]) # small gating MLP
selected = top_k(active, scores, budget[r])
if caching == "recursion-wise":
# build KV only for selected tokens
KV[r] = kv_from(block, H[selected])
H[selected] = block(H[selected], KV[r])
else:
H[selected] = block(H[selected], KV[1]) # reuse first-loop KV
active = selected # only selected tokens go deeper
return assemble_outputs(H) # exited tokens keep their last state
This captures the main mechanics described in the paper: a shared block, router-based token selection per depth, and two KV-cache options tuned for dynamic recursion. Implementation details (e.g., load-balancing losses and “Middle-Cycle” parameter sharing) are in the paper.
When you might consider MoR
-
You want vanilla-like quality at lower cost, or higher throughput at a given quality point.
-
You can support router training and depth-wise batching in your stack.
-
You’re comfortable with weight-tying (the paper finds “Middle-Cycle” sharing a safe choice).
Jargons
Pareto frontier: the set of best trade-offs between two goals (here, compute and quality). MoR pushes that line outward, giving more accuracy for the same compute, or the same accuracy for less compute.
References / further reading
-
Paper & abstract (July 2025): method overview, model scales, routing & KV-cache designs, training/inference results.
-
OpenReview PDF (tech details): routing (expert-choice vs token-choice), recursion-wise vs recursive KV sharing, reported numbers (accuracy, FLOPs, memory, throughput plots).
-
Official code (GitHub): implementation and checkpoints, README notes “up to 2x throughput” in the paper’s setup.